Работа со строками в Python
В файлах, как правило, у нас содержатся строки данных.
Я разобрался, как работать с файлами: Работа с файлами в python
Теперь нужно разобраться с тем, как манипулировать строками.
- Строка - это неизменяемая последовательность символов
Создание строк
- Для создания строки используются строковые литералы
- Существует несколько видов строковых литералов:
- Стандартные
- Необработанные
- Форматированные
Стандартные строковые литералы
- Стандартные строковые литералы
- это обычный фрагмент текста
>>> 'A single-line string in single quotes'
'A single-line string in single quotes'
- Для создания многостроковых строк (простите) используются тройные кавычки:
>>> '''A triple-quoted string
... spanning across multiple
... lines using single quotes'''
'A triple-quoted string\nspanning across multiple\nlines using single quotes'
>>> """A triple-quoted string
... spanning across multiple
... lines using double quotes"""
'A triple-quoted string\nspanning across multiple\nlines using double quotes'
Escape-последовательности
- Используются для того, чтобы отобразить какой-либо специальный символ (вроде
') в строке
>>> 'This string contains a single quote (\') character'
"This string contains a single quote (') character"
Экранирование символа
| Характер | Обычная интерпретация | Escape-последовательность | Сбежавшая интерпретация |
|---|---|---|---|
' |
Разграничивает строковый литерал | \' |
Буквальная одинарная кавычка ( ') характер |
" |
Разграничивает строковый литерал | \" |
Буквальная двойная кавычка ( ") характер |
<newline> |
Завершает строку ввода | \<newline> |
Новая строка игнорируется |
\ |
Вводит escape-последовательность | \\ |
Буквальная обратная косая черта ( \) характер |
Пример работы \: |
>>> "Hello\
... , World\
... !"
'Hello, World!'
Изменение поведения строк
| Escape-последовательность | Сбежавшая интерпретация |
|---|---|
\a |
ASCII Белл ( BEL) характер |
\b |
ASCII-пробел ( BS) характер |
\f |
ASCII-подача формы ( FF) характер |
\n |
ASCII-перевод строки ( LF) характер |
\N{<name>} |
Символ из базы данных Unicode с заданным <name> |
\r |
Возврат каретки ASCII ( CR) характер |
\t |
Вкладка ASCII «Горизонтально» ( TAB) характер |
\uxxxx |
Символ Юникода с 16-битным шестнадцатеричным значением xxxx |
\Uxxxxxxxx |
Символ Юникода с 32-битным шестнадцатеричным значением xxxxxxxx |
\v |
Вкладка ASCII «Вертикально» ( VT) характер |
\ooo |
Символ с восьмеричным значением ooo |
\xhh |
Символ с шестнадцатеричным значением hh |
Примеры:
>>> # Tab
>>> print("a\tb")
a b
>>> # Linefeed
>>> print("a\nb")
a
b
>>> # Octal
>>> print("\141")
a
>>> # Hex
>>> print("\x61")
a
>>> # Unicode by name
>>> print("\N{rightwards arrow}")
→
Необработанные строковые литералы
- С помощью них можно создавать строки, которые будут отображать все символы (вместо выполнения каких-либо действий как в escape последовательности)
>>> print("Before\tAfter") # Regular string
Before After
>>> print(r"Before\tAfter") # Raw string
Before\tAfter
Форматированные строковые литералы (f-строки)
- Позволяют "вставлять" значения переменных прямо в строку
>>> name = "Jane"
>>> f"Hello, {name}!"
'Hello, Jane!'
str()
- Чаще всего используется для преобразования значений из других типов в строку
>>> str([1, 2, 3])
'[1, 2, 3]'
>>> str({"one": 1, "two": 2, "three": 3})
"{'one': 1, 'two': 2, 'three': 3}"
>>> str({"A", "B", "C"})
"{'B', 'C', 'A'}
Операции над строками
Операторы
Объединение строк (+)
>>> greeting = "Hello"
>>> name = "Pythonista"
>>> greeting + ", " + name + "!!!"
'Hello, Pythonista!!!'
Повторение строк (*)
>>> "=" * 10
'=========='
>>> 10 * "Hi!"
'Hi!Hi!Hi!Hi!Hi!Hi!Hi!Hi!Hi!Hi!'
Более сложный пример с демонстрацией использования оператора *:
def display_table(data, headers):
max_len = max(len(header) for header in headers)
print(" | ".join(header.ljust(max_len) for header in headers))
sep = "-" * max_len
print("-|-".join(sep for _ in headers))
for row in data:
print(" | ".join(header.ljust(max_len) for header in row))
data = [
["Alice", "25", "Python Developer"],
["Bob", "30", "Web Designer"],
["Charlie", "35", "Team Lead"],
]
headers = ["Name", "Age", "Job Title"]
display_table(data,headers)
Name | Age | Job Title
----------|-----------|----------
Alice | 25 | Python Developer
Bob | 30 | Web Designer
Charlie | 35 | Team Lead
Поиск подстрок
in:
>>> "food" in "That's food for thought."
True
>>> "food" in "That's good for now."
False
not in:
>>> "z" not in "abc"
True
>>> "z" not in "xyz"
False
Функции для обработки строк
| Функция | Описание |
|---|---|
len() |
Возвращает длину строки |
str() |
Возвращает удобное строковое представление объекта. |
repr() |
Возвращает удобное для разработчиков строковое представление объекта. |
format() |
Позволяет форматировать строки |
ord() |
Преобразует символ в целое число |
chr() |
Преобразует целое число в символ |
Длина строки: len()
>>> len("Python")
6
Вывод значения в формате строки: str() и repr()
>>> str(42)
'42'
>>> str(3.14)
'3.14'
>>> str([1, 2, 3])
'[1, 2, 3]'
>>> str({"one": 1, "two": 2, "three": 3})
"{'one': 1, 'two': 2, 'three': 3}"
>>> str({"A", "B", "C"})
"{'B', 'C', 'A'}"
Идентичный вывод будет при применении repr()
Есть еще .__str__() и .__repr__(), но до них я еще не добрался, тк они используются в классах, а о классах, на данный момент, у меня совсем нет представления. Подробнее о разнице между ними можно прочитать здесь
Форматирование строк: format()
- Форматирование строк позволяет показать строку в нужном формате, например:
>>> import math
>>> from datetime import datetime
>>> format(math.pi, ".4f") # Four decimal places
'3.1416'
>>> format(1000000, ",.2f") # Thousand separators
'1,000,000.00'
>>> format("Header", "=^30") # Centered and filled
'============Header============'
>>> format(datetime.now(), "%a %b %d, %Y") # Date
'Mon Jul 29, 2024'
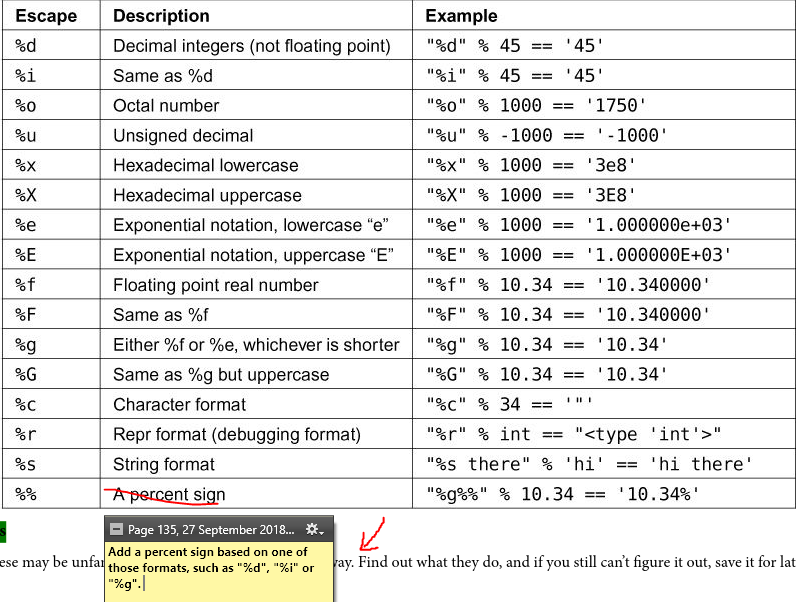
Cheatsheet:
Преобразование символов юникода в целочисленные значение: ord() и chr()
>>> ord("a")
97
>>> ord("#")
35
>>> ord("€")
8364
>>> ord("∑")
8721
>>> chr(97)
'a'
>>> chr(35)
'#'
>>> chr(8364)
'€'
>>> chr(8721)
'∑'
- Функции делают два противоположных действия:
ordпринимает символ и возвращает его код в таблице Unicodechrпринимает код из таблицы Unicode и возвращает символ